Program
Keynote Speakers



Conference Program
3DV 2019 will showcase high quality single-track oral and spotlight presentations. All papers will also be presented as posters. The main conference will run from September 17 to 19, in conjunction with the industrial exhibition, preceded by a tutorial on September 16.
At a glance
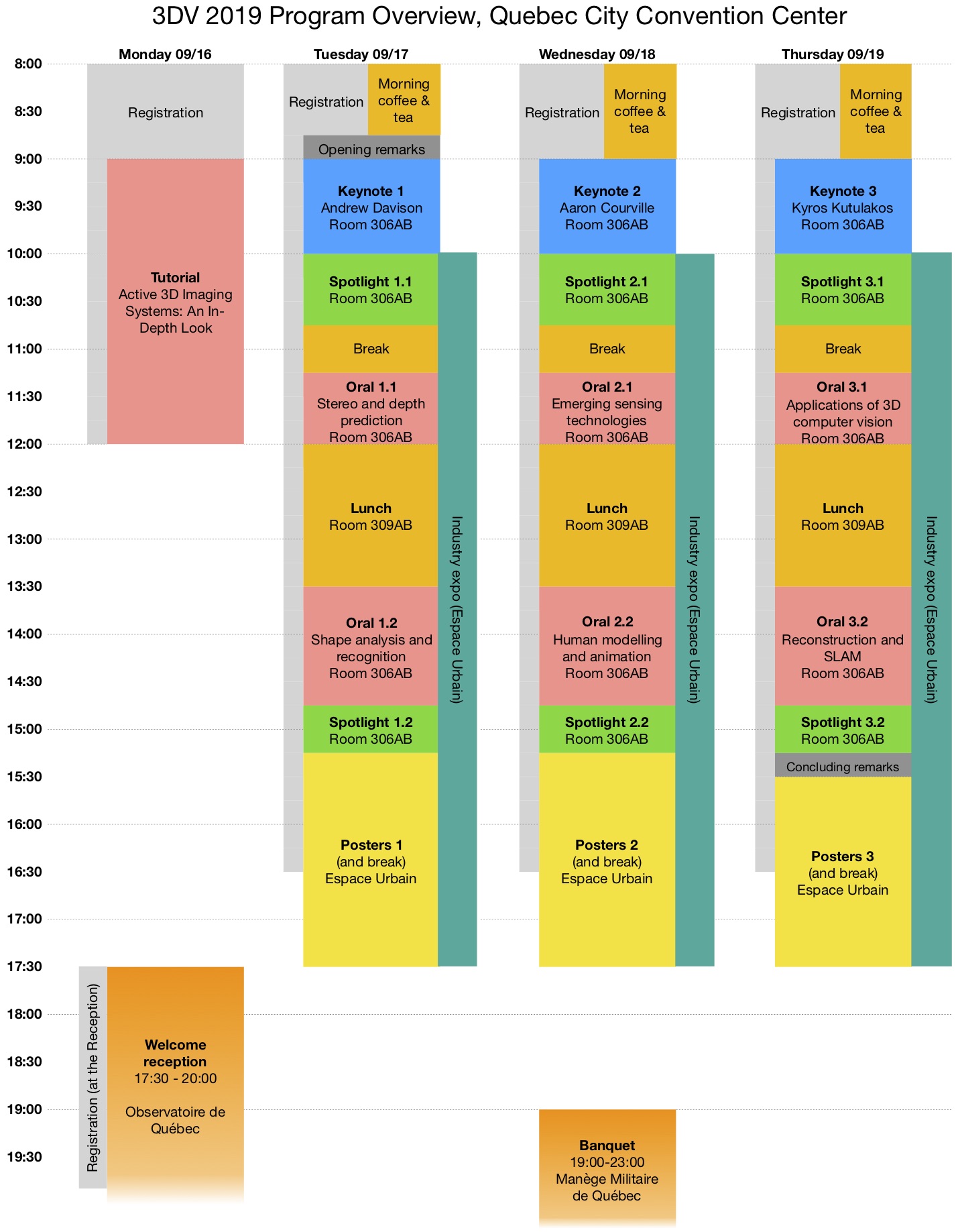
Monday, September 16, 2019
9:00-12:00 — Tutorial, Room 306AB
12:00-... — Lunch (on your own)
17:30-20:00 — Welcome Reception, Observatoire de la Capitale
Tuesday, September 17, 2019
8:00-9:00 — Morning Coffee and Tea, Hall 310
8:45-9:00 — Opening Remarks, Room 306AB
9:00-10:00 — Keynote 1: Andrew Davison (Imperial College London)
Room 306AB, Session chair: Edmond Boyer (INRIA Grenoble, France)
From SLAM to Spatial AI
To enable the next generation of smart robots and devices which can truly interact with their environments, Simultaneous Localisation and Mapping (SLAM) will progressively develop into a general real-time geometric and semantic 'Spatial AI' perception capability. I will give many examples from our work on gradually increasing visual SLAM capability over the years. However, much research must still be done to achieve true Spatial AI performance. A key issue is how estimation and machine learning components can be used and trained together as we continue to search for the best long-term scene representations to enable intelligent interaction. Further, to enable the performance and efficiency required by real products, computer vision algorithms must be developed together with the sensors and processors which form full systems, and I will cover research on vision algorithms for non-standard visual sensors as well as concepts for the longer term future of coupled algorithms and computing architectures.
10:00-17:30 — Industry Expo, Espace Urbain
10:00-10:45 — Spotlight Session 1.1
Room 306AB
-
Pano Popups: Indoor 3D Reconstruction with a Plane-Aware Network
-
IoU Loss for 2D/3D Object Detection
-
Pixel-Accurate Depth Evaluation in Realistic Driving Scenarios
-
SyDPose: Object Detection and Pose Estimation in Cluttered Real-World Depth Images Trained using only Synthetic Data
-
NoVA: Learning to See in Novel Viewpoints and Domains
-
Learning Depth from Endoscopic Images
-
Pairwise Attention Encoding for Point Cloud Feature Learning
-
PC-Net: Unsupervised Point Correspondence Learning with Neural Networks
-
A Unified Point-Based Framework for 3D Segmentation
-
Optimising for Scale in Globally Multiply-Linked Gravitational Point Set Registration Leads to Singularity
-
3D Neighborhood Convolution: Learning Depth-Aware Features for RGB-D and RGB Semantic Segmentation
10:45-11:15 — Break
11:15-12:00 — Oral Session 1.1: Stereo and depth prediction
Room 306AB, Session chair: Helge Rhodin (University of British Columbia, Canada)
-
MVS²: Deep Unsupervised Multi-view Stereo with Multi-View Symmetry
-
Fast Stereo Disparity Maps Refinement By Fusion of Data-Based And Model-Based Estimations
-
Structured Coupled Generative Adversarial Networks for Unsupervised Monocular Depth Estimation
12:00-13:30 — Lunch, Room 309AB
13:30-14:45 — Oral Session 1.2: Shape analysis and recognition
Room 306AB, Session chair: Yuichi Taguchi (Facebook, USA)
-
DispVoxNets: Non-Rigid Point Set Alignment with Supervised Learning Proxies
-
Correspondence-Free Region Localization for Partial Shape Similarity via Hamiltonian Spectrum Alignment
-
Effective Rotation-invariant Point CNN with Spherical Harmonics kernels
-
Structured Domain Adaptation for 3D Keypoint Estimation
-
Learning Point Embeddings from Shape Repositories for Few-Shot Segmentation
14:45-15:15 — Spotlight Session 1.2, Room 306AB
Room 306AB
-
To Complete or to Estimate, that is the Question: A Multi-task Approach to Depth Completion and Monocular Depth Estimation
-
Frequency Shift Triangulation: A Robust Fringe Projection Technique for 3D Shape Acquisition in the Presence of Strong Interreflections
-
Rotation Invariant Convolutions for 3D Point Clouds Deep Learning
-
Accurate and Real-time Object Detection based on Bird's Eye View on 3D Point Clouds
-
Photometric Segmentation: Simultaneous Photometric Stereo and Masking
-
High-Resolution Augmentation for Automatic Template-Based Matching of Human Models
Riccardo Marin; Simone Melzi; Emanuele Rodolà; Umberto Castellani -
V-NAS: Neural Architecture Search for Volumetric Medical Image Segmentation
Zhuotun Zhu; Chenxi Liu; Dong Yang; Alan Yuille; Daguang Xu
15:15-17:30 Poster Session 1 and Break, Espace Urbain
All oral and spotlight presenters also present a poster.
Wednesday, September 18, 2019
8:00-9:00 — Morning Coffee and Tea, Hall 310
9:00-10:00 — Keynote 2: Aaron Courville (University of Montreal)
Room 306AB, Session chair: Denis Laurendeau (Université Laval, Canada)
Progress in Unsupervised Domain Alignment with Generative Adversarial Networks
There has been a great deal of recent progress in the development of Deep Generative Models for images and video. One such development is the introduction of adversarial training strategies for neural network-based generative models (GANs). Beyond the sometimes stunning images that GANs have been shown to generate, methods such as CycleGAN have demonstrated how to exploit adversarial training to perform unpaired image-to-image translation with remarkable results. These methods open the door to a wide range of novel applications and change the way we think about how we use data and -- to some extent -- challenge our need for supervision.
In this talk I will endeavour to present a sober view on the progress achieved thus far. I will discuss some of the limitations of these methods and outline our recent attempts to overcome them. In particular, I'll consider how we can learn translations between domains that are imbalanced or that exhibit mutually independent factors of variation. I also hope to discuss preliminary work leveraging limited supervision to establish more semantic couplings between domains.
10:00-17:30 — Industry Expo, Espace Urbain
10:00-10:45 — Spotlight Session 2.1
Room 306AB
-
Revisiting Depth Image Fusion with Variational Message Passing
-
Distributed Surface Reconstruction from Point Cloud for City-Scale Scenes
-
Web Stereo Video Supervision for Depth Prediction from Dynamic Scenes
-
Learning to Refine 3D Human Pose Sequences
-
Reconstruction of As-is Semantic 3D Models of Unorganised Storehouses
-
Dynamic Surface Animation using Generative Networks
-
Decoupled Hybrid 360° Panoramic Stereo Video
-
Unsupervised Feature Learning for Point Cloud Understanding by Contrasting and Clustering Using Graph Convolutional Neural Networks
-
Multi-Person 3D Pose Estimation
-
Optimal, Non-Rigid Alignment for Feature-Preserving Mesh Denoising
-
Enhancing Self-supervised Monocular Depth Estimation with Traditional Visual Odometry
10:45-11:15 — Break
11:15-12:00 — Oral Session 2.1: Emerging sensing technologies
Room 306AB, Session chair: Marc-Antoine Drouin (NRC, Canada)
-
Learning to Think Outside the Box: Wide-Baseline Light Field Depth Estimation with EPI-Shift
-
360 Surface Regression with a Hyper-Sphere Loss
-
Asynchronous Multi-Hypothesis Tracking of Features with Event Cameras
12:00-13:30 — Lunch, Room 309AB
Room 309AB
13:30-14:45 — Oral Session 2.2: Human modelling and animation
Room 306AB, Session chair: Marco Volino (University of Surrey, UK)
-
Towards Accurate 3D Human Body Reconstruction from Silhouettes
-
Progression Modelling for Online and Early Gesture Detection
-
Predicting Animation Skeletons for 3D Articulated Models via Volumetric Nets
-
Motion Capture from Pan-Tilt Cameras with Unknown Orientation
-
Convex Optimisation for Inverse Kinematics
14:45-15:20 — Spotlight Session 2.2
Room 306AB
-
Creating Realistic Ground Truth Data for the Evaluation of Calibration Methods for Plenoptic and Conventional Cameras
Tim Michels; Arne Petersen; Reinhard Koch -
Multi-Spectral Visual Odometry without Explicit Stereo Matching
-
Simultaneous Shape Registration and Active Stereo Shape Reconstruction using Modified Bundle Adjustment
-
Semantic Segmentation of Sparsely Annotated 3D Point Clouds by Pseudo-labelling
-
SIR-Net: Scene-Independent End-to-End Trainable Visual Relocalizer
-
Light Field Compression using Eigen Textures
-
Res3ATN - Deep 3D Residual Attention Network for Hand Gesture Recognitionin Videos
-
Physics-Aware 3D Mesh Synthesis
15:20-17:30 — Poster Session 2 and Break, Espace Urbain
All oral and spotlight presenters also present a poster.
19:00-23:00 — Conference Banquet, Manège Militaire
Thursday, September 19, 2019
8:00-9:00 — Morning Coffee and Tea, Hall 310
9:00-10:00 — Keynote 3: Kyros Kutulakos (University of Toronto)
Room 306AB, Session chair: Guy Godin (NRC, Canada)
Rethinking Structured Light
Even though structured-light triangulation is a decades-old problem, much remains to be discovered about it---with potential ramifications for computational imaging more broadly.
I will focus on two specific aspects of the problem that are influenced by recent developments in our field. First, programmable coded-exposure sensors vastly expand the degrees of freedom of an imaging system, essentially redefining what it means to capture images under structured light. I will discuss our efforts to understand the theory and expanded capabilities of such systems, and to build custom CMOS sensors that realize them. Second, I will outline our recent work on turning structured-light triangulation into an optimal encoding-decoding problem derived from first principles. This opens the way for adaptive systems that can learn on their own how to optimally control their light sources and sensors, and how to convert the images they capture into accurate 3D geometry.
10:00-17:30 — Industry Expo, Espace Urbain
10:00-10:45 — Spotlight Session 3.1
Room 306AB
-
On the Redundancy Detection in Keyframe-based SLAM
-
SIPs: Succinct Interest Points from Unsupervised Inlierness Probability Learning
-
On Object Symmetries and 6D Pose Estimation from Images
-
AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects
-
UnDispNet: Unsupervised Learning for Multi-Stage Monocular Depth Prediction
-
360-degree Textures of People in Clothing from a Single Image
-
Adaptive-resolution Octree-based Volumetric SLAM
-
Multimodal 3D Human Pose Estimation from a Single Image
-
Effective Convolutional Neural Network Layers in Flow Estimation for Omni-directional Images
-
Learning to Translate Between Real World and Simulated 3D Sensors While Transferring Task Models
-
Spherical View Synthesis for Self-Supervised 360° Depth Estimation
10:45-11:15 — Break
11:15-12:00 — Oral Session 3.1: Applications of 3D computer vision
Room 306AB, Session chair: Evangelos Kalogerakis (University of Massachusetts Amherst, USA)
-
Sparse-to-Dense Hypercolumn Matching for Long-Term Visual Localization
-
Unified Underwater Structure-from-Motion
-
Learned Multi-View Texture Super-resolution
12:00-13:30 — Lunch, Room 309AB
13:30-14:45 — Oral Session 3.2: Reconstruction and SLAM
Room 306AB, Session chair: Scott Spurlock (Elon University, USA)
-
Online Stability Improvement of Groebner Basis Solvers using Deep Learning
-
Surface Reconstruction from 3D Line Segments
-
Let's Take This Online: Adapting Scene Coordinate Regression Network Predictions for Online RGB-D Camera Relocalisation
-
Mobile Photometric Stereo Combined with SLAM for Dense 3D Reconstruction
-
Location Field Descriptors: Single Image 3D Model Retrieval in the Wild
14:45-15:15 — Spotlight Session 3.2
Room 306AB
-
Adaptive Mesh Texture for Multi-View Appearance Modeling
-
Real-time Multi-material Reflectance Reconstruction for Large-scale Scenes under Uncontrolled Illumination from RGB-D Image Sequences
-
Language2Pose: Natural Language Grounded Pose Forecasting
-
Synthesizing Diverse Lung Nodules Wherever Massively: 3D Multi-Conditional GAN-based CT Image Augmentation for Object Detection
-
Multiple Point Light Estimation from Low-Quality 3D Reconstructions
-
Fast Non-Convex Hull Computation
-
Incorporating 3D Information into Visual Question Answering
15:15-15:30 — Concluding Remarks
Room 306AB
15:30-17:30 — Poster Session 3 and Break, Espace Urbain
All oral and spotlight presenters also present a poster.
Tutorials
September 16, 2019, 09:00 - 12:00, Room 306AB
-
Active 3D Imaging Systems: An In-Depth Look
Tutorial outlook:
The objectives of the tutorial are to provide an advanced understanding of the principles and properties of 3D active imaging sensors, in particular but not exclusively those using triangulation with structured light. The tutorial will cover the basic principles of 3D imaging systems, explore their specific properties and performance, as well as their limitations. Moreover, it will help researchers interested in the modeling and analysis of 3D data better understand the physical processes underlying their input data. Examples of the advantages of including this physical knowledge within modeling and analysis tasks will be given.
Presentation Instructions
Oral presentations
- Oral presenters (except spotlights) can use their own laptop. VGA and HDMI connectivity are available (please bring your own adapters). A conference laptop will also be available (Windows with Powerpoint only).
- The projector will be set up for the 16:9 format using a 1920x1080 (full HD) resolution.
- Oral talks are allowed 12 minutes. Since the sessions are packed, this will be strictly enforced. You must leave the podium once your time is up.
- Additional 3 minutes are allocated for questions by the audience, switching between speakers and introducing the next speaker.
- Oral presenters are also required to present a poster during the poster session on the same day as the oral presentation.
Spotlight presentations
- All papers accepted as posters are also presented in the "spotlight" session.
- Spotlight presenters are required to send a video recording of their slides in MP4 format using a 16:9 format at a resolution of 1920x1080 (full HD), with H.264 video encoding (no audio).
- The video will be played from the control room, so there is no need to connect your laptop.
- The audio channel from your submitted video will NOT be used: you are still required to present the slides orally as your video plays.
- The recording must not exceed 3 minutes and 50 seconds. Longer videos will be truncated. The next speaker's video will start at exactly 4 minutes after the beginning of your own video. Timing will be strictly enforced.
- The session chairs will NOT be introducing each spotlight video. Thus, start your video with a title slide and introduce yourself.
- Create a single MP4 file named PAPERNUMBER.mp4 where PAPERNUMBER is your 3DV 2019 paper number.
- Put the MP4 file in a place where it is sharable (e.g. Dropbox, OneDrive, FTP server, etc…) and send the link by e-mail to 3dv19tutorials@3dv.org.
- The deadline is September 6, 2019, anywhere on earth.
Poster sessions
- Poster boards have a useable dimension of 92 (height) x 183 (width) cm. Please use a horizontal layout as those tend to occupy the space better.
- Before your poster session begins, please identify the number of your poster in the program and attach the poster to the corresponding stand. A label indicating your paper ID will be placed on the top of your board space. Check with the volunteers or the registration desk if you cannot find your poster stand.
- Tacks and technical equipment will be available for the mounting of posters.
- Please remove your poster after the session ends.
- A poster printing service is not available at the conference, but you can use Planete Multi-Services (15-mins walk from the Convention Center).